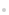═©ą┼ĮńėŹ ╬─╔·łDį┌ūŅĮ³ę╗─Ļ╚ĪĄ├┴╦’@ų°Ą─▀M▓ĮŻ¼DreamBooth Č©ųŲ╗»╔·│╔╣żū„Ż¼▀Mę╗▓ĮūC├„┴╦╬─╔·łDĄ─Øō┴”Ż¼▓óŪęÅVĘ║ę²Ų┴╦╔ńģ^(q©▒)ĻPūóŻ¼ŽÓ▒╚ė┌å╬Ė┼─Ņ╔·│╔Ż¼į┌ę╗ÅłłDā╚Č©ųŲČÓéĆĖ┼─Ņ╩ŪĖ³╝ėėą╚żŪęŠ▀ėąÅVĘ║æ¬ė├ł÷Š░Ż©AI ė░śŪŻ¼AI ┬■«ŗ╔·│╔....Ż®ĪŻ
ŽÓ▒╚ė┌å╬Ė┼─ŅČ©ųŲ╔·│╔╚ĪĄ├Ą─│╔╣”Ż¼░ó└’╠ß│÷Ą─ Cones ║═ Adobe ╠ß│÷Ą─ Custom Diffusion ū„×ķ¼F(xi©żn)ėąĄ─ČÓČ©ųŲĖ┼─Ņ╔·│╔ĘĮĘ©╚į┤µį┌ā╔éĆ╠¶æ(zh©żn)Ż║
-
╩ūŽ╚Ż¼╦¹éāąĶę¬×ķ├┐ę╗ĘNČÓéĆĖ┼─ŅĄ─ĮM║ŽČ╝īW┴Ģå╬¬ÜĄ──Żą═Ż¼▀@┐╔─▄Ģ■╩▄ĄĮęįŽ┬ė░ĒæŻ║1Ż®¤oĘ©└¹ė├ęčėąĄ──Żą═Ż¼▒╚╚ńę╗éĆą┬Ą─ąĶę¬Č©ųŲĄ─ČÓĖ┼─ŅĮM░³║¼╚²ĘNĖ┼─Ņ {A,B,C}Ż¼¤oĘ©Å─ęčėąĄ─ {A,B} Ą─Č©ųŲ─Żą═ųą½@Ą├ų¬ūRŻ¼ų╗─▄ųžą┬ė¢ŠÜĪŻ2Ż®«öąĶę¬Č©ųŲĄ─Ė┼─ŅöĄ(sh©┤)┴┐į÷╝ėĢrŻ¼ėŗ╦Ń┘Yį┤Ą─Ž¹║─ųĖöĄ(sh©┤)╔Ž╔²ĪŻ
╗∙ė┌┤╦Ż¼░ó└’░═░═║═╬øŽü╝»łFĄ─蹊┐łFĻĀ╠ß│÷┴╦ĮM║Ž╩ĮĄ─ČÓĖ┼─ŅČ©ųŲ╔·│╔ĘĮĘ©Ż║Cones 2Ż¼─▄═¼ĢrČ©ųŲĖ³ČÓ╬’¾wŻ¼Ūę╔·│╔łDŲ¼┘|┴┐’@ų°╠ß╔²ĪŻ

šō╬─ų„ĒōŻ║Cone 2
https://arxiv.org/abs/2305.19327
ĒŚ─┐ų„ĒōŻ║Cones-page
https://cones-page.github.io
įōłFĻĀĄ─Ū░ū„ Cones ½@Ą├┴╦ ICML 2023 Ą─ oralŻ¼▓óŪęį┌═Ų╠ž½@Ą├┴╦ÅVĘ║ĻPūóĪŻ

Cones 2 ā×(y©Łu)ä▌ų„ę¬¾w¼F(xi©żn)į┌ 3 éĆĘĮ├µĪŻŻ©1Ż®╩╣ė├║åå╬Č°ėąą¦Ą─ĘĮĘ©üĒ▒Ē╩ŠĖ┼─ŅŻ¼┐╔ęį╚╬ęŌĮM║ŽŻ¼Å═ė├Ė„ĘNė¢ŠÜ║├å╬Ė┼─ŅŻ¼Å─Č°▀MąąČÓČ©ųŲĖ┼─Ņ╔·│╔Ż¼Č°¤oąĶ×ķČÓĖ┼─Ņ▀Mąą╚╬║╬ųžą┬ė¢ŠÜĪŻŻ©2Ż®╩╣ė├┐šķg▓╝Šųū„×ķųĖī¦Ż¼▀@į┌īŹ█`ųąĘŪ│Ż╚▌ęū½@Ą├Ż¼ė├æ¶ų╗ąĶę¬╠ß╣®ę╗éĆ bounding boxŻ¼╝┤┐╔ęį┐žųŲ├┐éĆĖ┼─ŅĄ─╠žČ©╬╗ų├Ż¼▓ó═¼Ģr£p▌pĖ┼─Ņų«ķgĄ─ī┘ąį╗ņŽ²ĪŻŻ©3Ż®į┌ę╗ą®Š▀ėą╠¶æ(zh©żn)ąįĄ─ł÷Š░Ž┬ę▓─▄╚ĪĄ├┴Ņ╚╦ØMęŌĄ─ąį─▄Ż║▀MąąšZ┴xŽÓ╦ŲĄ─ČÓČ©ųŲĖ┼─ŅĄ─╔·│╔Ż¼╚ńČ©ųŲā╔ų╗╣ĘŻ¼▓óŪę┐╔ęįĮ╗ōQč█ńRŻ╗į┌Ė┼─ŅöĄ(sh©┤)┴┐╔ŽŻ¼ę▓┐╔ęį║Ž│╔┴∙éĆĖ┼─ŅĪŻ

ĘĮĘ©
1. ╗∙ė┌öU╔ó─Żą═Ą─╬─▒Šę²ī¦łDŽ±╔·│╔
öU╔ó─Żą═īW┴ĢÅ─š²æB(t©żi)Ęų▓╝įļ┬Ģųąų▓Į╚źįļüĒ╗ųÅ═šµīŹĄ─ęĢėXā╚╚▌Ż¼įō▀^│╠īŹļH╔Ž╩Ūį┌─ŻöM┐╔─µĄ─ķLČ╚×ķ T=1000 Ą─±RĀ¢┐╔Ę“µ£ĪŻį┌╬─▒ŠĄĮłDŽ±╚╬äšųąŻ¼Śl╝■öU╔ó─Żą═ Ą─ė¢ŠÜ─┐ś╦┐╔ęį║å╗»×ķųžĮ©ōp╩¦Ż║
╬─▒ŠŪČ╚ļ ═©▀^Į╗▓µūóęŌ┴”ÖCųŲūó╚ļĄĮ─Żą═ ųąĪŻį┌═Ų└ĒĢrŻ¼ŠW(w©Żng)Įj═©▀^Ą³┤·╚źįļ ▀Mąą▓╔śėĪŻ
2. Üł▓Ņ╬─▒ŠŪČ╚ļ▒Ē╩ŠĖ┼─Ņ
×ķ┴╦┐╔ęįČ©ųŲ╗»╔·│╔ė├æ¶ąĶꬥ─╠žČ©Ė┼─ŅŻ¼─Żą═╩ūŽ╚ąĶę¬Ī░ėøūĪĪ▒▀@ą®Ė┼─ŅĄ─╠žš„ĪŻė╔ė┌Ė─ūāŅAė¢ŠÜ─Żą═ģóöĄ(sh©┤)═∙═∙Ģ■ī¦ų┬─Żą═Ą─Ę║╗»ąįŽ┬ĮĄŻ¼Cones 2 ▀xō±ßśī”├┐éĆ╠žČ©Ė┼─ŅīW┴Ģę╗éĆ║Ž▀mĄ─ŠÄ▌ŗĘĮŽ“ĪŻīó▀@éĆĘĮŽ“ū„ė├ė┌Ė┼─Ņī”æ¬Ą─╗∙ŅÉĄ─╠žš„ŠÄ┤a╔ŽŻ¼Š═┐╔ęįĄ├ĄĮČ©ųŲ╗»Ą─ĮY╣¹Ż¼▀@éĆĘĮŽ“ĘQ×ķ residual token embeddingĪŻ
┼eéĆ└²ūėŻ¼į┌╩╣ė├ Stable Diffusion ╔·│╔łDŽ±Ī░ę╗ų╗╣Ęū°į┌║Ż×®╔ŽĪ▒ĢrŻ¼š¹éĆ╔·│╔▀^│╠ė╔╬─▒ŠĮø(j©®ng)▀^╬─▒ŠŠÄ┤a─Żą═Ą├ĄĮĄ─╬─▒ŠŠÄ┤a┐žųŲŻ¼─Ū├┤ų╗ąĶę¬īóĪ░╣ĘĪ▒ī”æ¬Ą─╬─▒ŠŠÄ┤aū÷║Ž▀mĄ─Ų½ęŲŻ¼Š═┐╔ęįūī─Żą═╔·│╔│÷Č©ųŲ╗»Ą─Ī░╣ĘĪ▒ĪŻ×ķ┴╦Ą├ĄĮ residual token embeddingŻ¼╩ūŽ╚ąĶę¬ė├ĮoČ©Ą─öĄ(sh©┤)ō■(j©┤)╬óš{╬─▒ŠŠÄ┤a─Żą═Ż¼į┌ė¢ŠÜ▀^│╠ųą Cones 2 ═©▀^ę²╚ļ╬─▒ŠŠÄ┤a▒Ż│ųōp╩¦Ż¼Ž▐ųŲ╬óš{║¾Ą─╬─▒ŠŠÄ┤aŲ„Ą─▌ö│÷║═įŁ╩╝ŅAė¢ŠÜĄ─╬─▒ŠŠÄ┤aŲ„Ą─▌ö│÷▒M┐╔─▄ĮėĮ³ĪŻ
═¼śėģó┐╝╔Ž├µĄ─└²ūėŻ¼ĮoČ©Ī░ę╗ų╗╣Ęū°į┌║Ż×®╔ŽĪ▒ū„×ķ▌ö╚ļŻ¼▀@ā╔éĆ╬─▒ŠŠÄ┤aŲ„▌ö│÷Ą─╬─▒ŠŠÄ┤aŻ¼ų╗į┌Č©ųŲ╗»Ė┼─Ņī”æ¬Ą─ŅÉäeį~Ż©╣ĘŻ®▀@└’▓Ņäe▌^┤¾Ż¼į┌Ųõ╦¹į~Ż©║Ż×®Ą╚ĪŻĪŻĪŻŻ®Ą─▓┐Ęų▒M┐╔─▄▒Ż│ų▌ö│÷ę╗ų┬ĪŻĮY║ŽįŁ▒ŠĄ─╔·│╔─Żą═Ż¼╬óš{║¾Ą─╬─▒ŠŠÄ┤aŲ„Š▀ėąČ©ųŲ╠žČ©Ė┼─ŅĄ──▄┴”Ż¼ė╔ė┌╬óš{▀^│╠▓╔ė├┴╦╬─▒ŠŠÄ┤a▒Ż│ųōp╩¦Ą─╝s╩°Ż¼▀@ĘN─▄┴”┐╔ęį═©▀^ėŗ╦Ń╬óš{▀^Ą─╬─▒ŠŠÄ┤aŲ„║═įŁ╩╝╬─▒ŠŠÄ┤aŲ„į┌ŅÉäeį~▓┐ĘųĄ─ŲĮŠ∙▓Ņ«ÉŻ¼üĒĄ├ĄĮąĶꬥ─ residual token embeddingŻ║
╗∙ė┌╔Ž╩÷ĘĮĘ©Ą├ĄĮÜł▓Ņ▒Ē╩ŠŻ¼╩Ū┐╔ęįųžÅ═╩╣ė├▓óŪę╝┤▓Õ╝┤ė├Ą─ĪŻį┌ū÷ČÓĖ┼─ŅČ©ųŲ╗»╔·│╔Ą─Ģr║“Ż¼ų╗ąĶę¬īó├┐éĆČ©ųŲĖ┼─Ņ╦∙ī”æ¬ŅÉäeį~Ą─╬─▒ŠŠÄ┤a╝ė╔Žī”æ¬Ą─Üł▓ŅĒŚ╝┤┐╔ĪŻ
3. ═©▀^┐šķg▓╝Šųę²ī¦ČÓĖ┼─ŅĮM║Ž╔·│╔
Į╗▓µūóęŌ┴”īėų«ķgĄ─ūóęŌ┴”łD╚ńŽ┬ Ż¼Į╗▓µūóęŌ┴”łDų▒Įėė░ĒæūŅĮK╔·│╔Ą─┐šķg▓╝ŠųŻ¼ČÓĖ┼─ŅČ©ųŲ╔·│╔Ą─łDŲ¼ųąĄ─ę╗éĆå¢Ņ}╩Ū─│ą®Ė┼─Ņ┐╔─▄¤oĘ©’@╩ŠĪŻ×ķ┴╦▒▄├Ō▀@ĘNŪķørŻ¼Cones 2 į┌ŽŻ═¹Ųõ│÷¼F(xi©żn)╝┤ė├æ¶═©▀^ bounding box ųĖČ©Ą─ģ^(q©▒)ė“ųąį÷ÅŖ─┐ś╦Ė┼─ŅĄ─╝ż╗ŅųĄĪŻ┴Ēę╗éĆå¢Ņ}╩ŪĖ┼─ŅķgĄ─ī┘ąį┤µį┌╗ņŽ²Ż¼╝┤╔·│╔łDŽ±ųąĄ─Ė┼─Ņ┐╔─▄░³║¼Ųõ╦¹Ė┼─ŅĄ─╠žš„ĪŻ
×ķ┴╦▒▄├Ō▀@ĘNŪķørŻ¼ätŽŻ═¹Ž„╚§├┐éĆī”Ž¾│÷¼F(xi©żn)į┌ė├æ¶ųĖČ©ģ^(q©▒)ė“═ŌĄ─╝ż╗ŅųĄĪŻĮY║Ž╔Ž╩÷ā╔ĘNŽļĘ©Ż¼Cones 2 ╠ß│÷┴╦ę╗ĘNĖ∙ō■(j©┤)ŅAČ©┴x▓╝Šų ųĖī¦╔·│╔▀^│╠Ą─ĘĮĘ©ĪŻį┌īŹ█`ųąŻ¼īó▓╝Šų Č©┴x×ķę╗ĮMĖ┼─Ņ▀ģĮń┐“Ż¼ė╔├┐éĆĖ┼─ŅĄ─Ą─ųĖī¦▓╝Šų ĮM│╔ĪŻį┌ŽŻ═¹Ė┼─Ņ │÷¼F(xi©żn)Ą─ģ^(q©▒)ė“ųąīó Ą─ųĄįOų├×ķš²ųĄŻ¼▓óį┌┼cįōĖ┼─Ņ¤oĻPģ^(q©▒)ė“ųąīó Ą─ųĄįOų├×ķžōĪŻī”ūóęŌ┴”łD▀MąąŠÄ▌ŗĪŻ
īŹ“×
īó╔·│╔ĮY╣¹┼c¼F(xi©żn)ėąĘĮĘ©▀Mąąī”▒╚Ż¼Å─ė¢ŠÜĄ─ėŗ╦ŃÅ═ļsČ╚Ż¼ęį╝░╔·│╔ą¦╣¹Ż¼Š∙ėą’@ų°╠ß╔²ĪŻ



▓óŪęį┌╠Ä└ĒĖ³ČÓĖ┼─ŅĄ─╔·│╔Ż¼ęį╝░╠Ä└ĒšZ┴xŽÓ╦Ų╬’¾wĄ─ł÷Š░Ž┬Ż¼Č╝ėąų°ā×(y©Łu)įĮ▒Ē¼F(xi©żn)ĪŻ

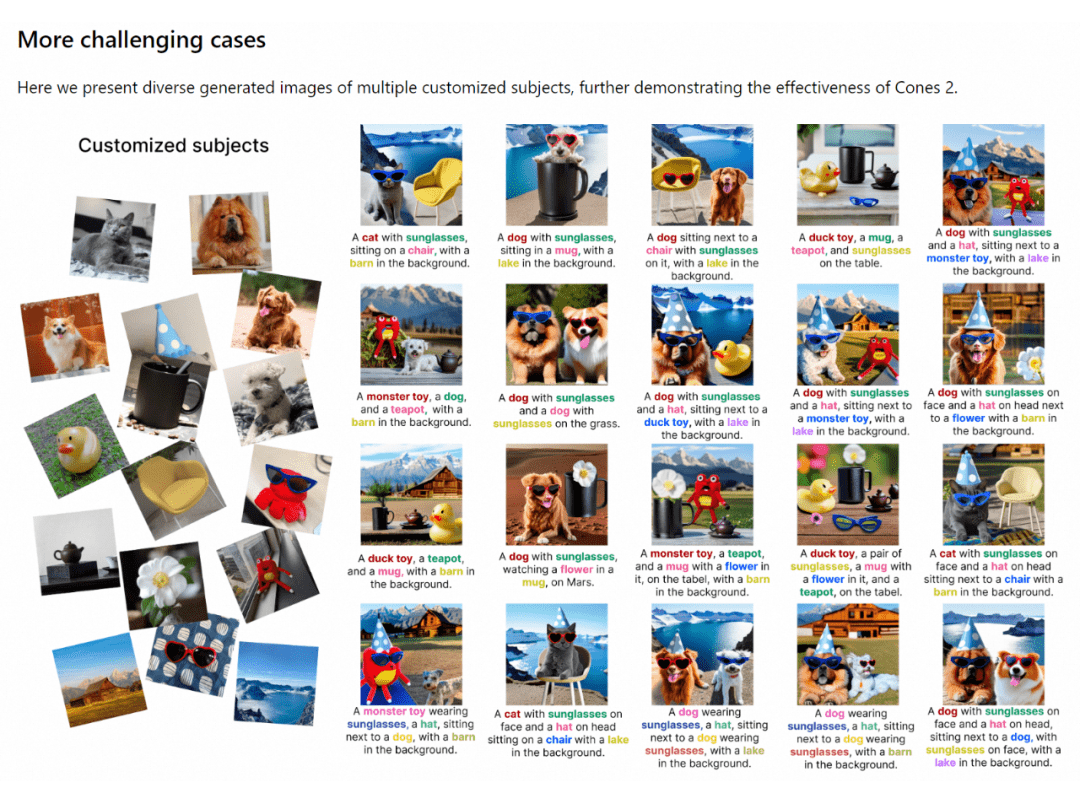
æ¬ė├Ū░Š░
ČÓČ©ųŲĖ┼─Ņ╔·│╔│²┴╦─▄ē“╔·│╔Ė³╝ėĖ▀┘|┴┐Ż¼ā╚╚▌žSĖ╗Ą─łDŲ¼═ŌŻ¼═¼ĢrŠ▀ėąÅVĘ║Ą─æ¬ė├Ū░Š░Ż¼¼F(xi©żn)į┌┤¾╗Ą─ ControlNet Ė³ČÓ╩Ū┐žųŲ╔·│╔łDŲ¼ųąĄ─ĮYśŗŻ¼ČÓĖ┼─ŅČ©ųŲ╔·│╔┐╔ęįī”╔·│╔Ą─ā╚╚▌▀Mąą┐žųŲŻ¼╩╣╬─▒ŠĄĮłDŽ±Ą─╔·│╔Ė³╝ė┐╔┐žŻ¼▀Mę╗▓Į╠ßĖ▀┴╦╬─╔·łD─Żą═Ą─æ¬ė├ārųĄĪŻ▒╚╚ńŻ¼äō(chu©żng)ū„š▀═©▀^▌ö╚ļ╬─▒ŠŻ¼═©▀^ÄūéĆČ©ųŲ║├Ą─ĮŪ╔½Ė┼─ŅŻ¼▀MąąČÓĖ±┬■«ŗ╔·│╔Ż╗═©▀^ĮM║Žė├æ¶Č©ųŲĄ─ūį╔ĒĮŪ╔½Ė┼─Ņ║═╔╠╝ę╠ß╣®Ą─ČÓéĆįć┤„įć┤®Ą─Č©ųŲĖ┼─ŅŻ©ę┬Ę■Ż¼╩ū’ŚŻ¼ą¼├▒Ą╚Ą╚Ż®Ż¼īŹ¼F(xi©żn)ČÓ┐ŅĘ■čbĄ─įć┤®¾w“×ĪŻ